Build Chatbot Frontend
In the previous lab, we configured and hosted the backend API code locally. The backend API integrates Azure Cosmos DB and Azure OpenAI. Now, let's focus on the front-end web application. This application is a single page application (SPA) written in React.
Connect Chatbot FrontEnd with BackEnd API
-
The frontend chatbot app is located in
apps/chatbot. update backend url in.envfile. While the code for the SPA web application is outside the scope of this dev guide. It's worth noting that the Web App is configured with the URL for the Backend API in.env.infoIf you are running the
codespacesin web browser, please replace theBACKEND_URIwith the actualcodespacesurl of backend, similar to below. Make sure no trailing slash in URL.BACKEND_URI=https://ominous-space-goldfish-v6vv749557wjfxj99-5000.app.github.devIf you are running the
codespacesinVS Code, you can keepBACKEND_URIas localhost.BACKEND_URI=http://localhost:5000 -
Start the app with below commands, open browser and visit url: http://localhost:4000/.
npm run dev -
Take your time and have a look at these files:
apps\chatbot\scr\api.index.tspoints to backend apiapps\chatbot\scr\pages\chat\Chat.tsxmanages chat conversationsapps\chatbot\scr\components\Answer\Answer.tsxmanages chat response
-
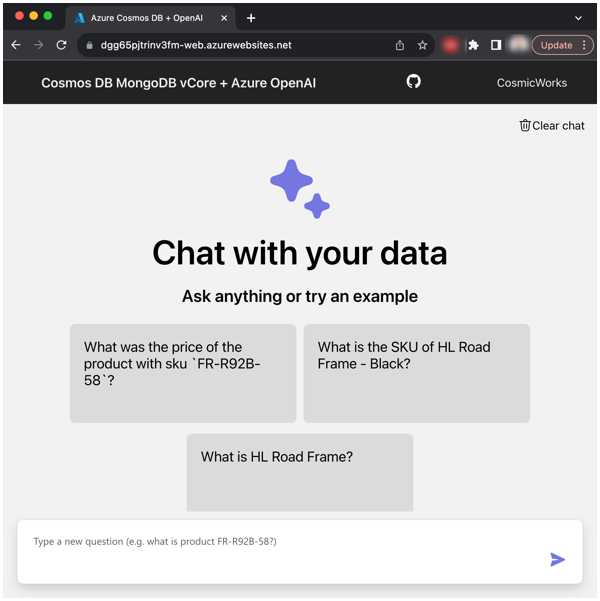
Navigating to local URL in the browser accesses the front-end application. Through this front-end application User Interface, questions can be submitted to the Azure OpenAI model about the Bike Store company data, then it will generate responses accordingly.
Ask questions about data and observe the responses
-
To ask the AI questions about the Bike Store company data, type the questions in to the front-end application chat user interface. The web application includes tiles with a couple example questions to get started. To use these, simply click on the question tile and it will generate an answer.
-
These example questions are:
- What was the price of the product with sku
BK-T79U-46? - What is the SKU of HL Road Frame - Black?
- What is HL Road Frame?
- What was the price of the product with sku
-
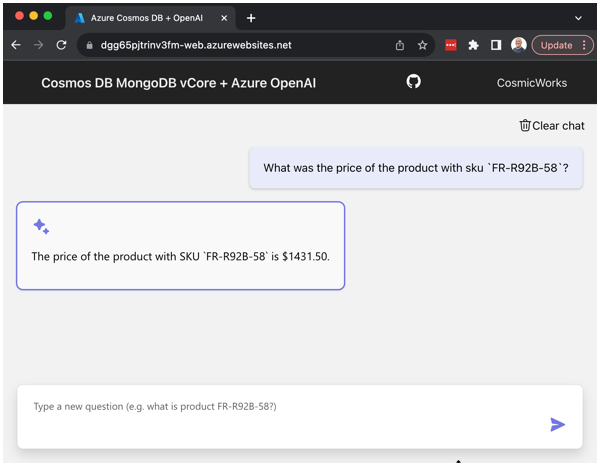
The chat user interface presents as a traditional chat application style interface when asking questions.
-
Go ahead, ask the service a few questions about Bike Store and observe the responses.
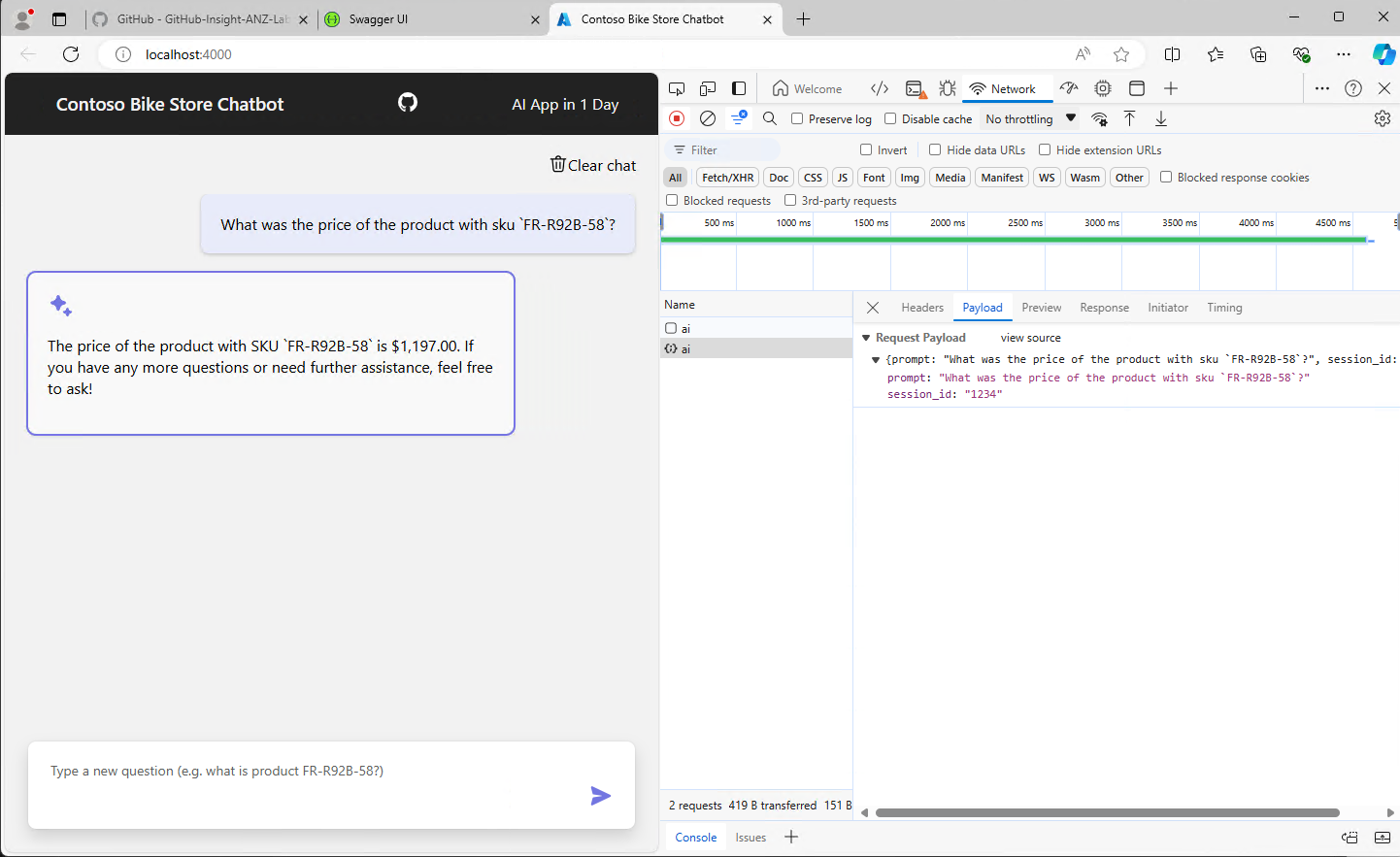
infoWhat do the HTTP and RESTful request & responses look like? Use the browser's developer tools to inspect the actual request and response payloads.
More things to think about
What do I do if the responses are incorrect?
It's important to remember the model is pre-trained with data, given a system message to guide it, in addition to the company data it has access to via Azure Cosmos DB. There are times when the Azure OpenAI model may generate an incorrect response to the prompt given that is either incomplete or even a hallucination (aka includes information that is not correct or accurate).
There are a few options of how this can be handled when the response is incorrect:
- Provide a new prompt that includes more specific and structured information that can help the model generate a more accurate response.
- Include more data in the library of company information the model has access to. The incorrect response may be a result of data or information about the company that is missing currently.
- Use Prompt Engineering techniques to enhance the System message and/or Supporting information provided to guide the model.
While it may be simple to ask the model questions, there are times when Prompt Engineering skills may be necessary to get the most value and reliable responses from the AI model.
What happens when I start exceeding my token limits?
A Token in Azure OpenAI is a basic unit of input and output that the service processes. Generally, the models understand and process text by breaking it down into tokens.
For example, the word hamburger gets broken up into the tokens ham, bur and ger, while a short and common word like pear is a single token. Many tokens start with a whitespace, for example hello and bye.
The total number of tokens processed in a given request depends on the length of the input, output and request parameters. The quantity of tokens being processed will also affect the response latency and throughput for the models.
The pricing of the Azure OpenAI service is primarily based on token usage.
Exceeding Token Quota Limits
Azure OpenAI has tokens per minute quota limits on the service. This quota limit, is based on the OpenAI model being used and the Azure region it's hosted in.
The Azure OpenAI Quotas and limits documentation contains further information on the specific quotas per OpenAI model and Azure region.
If an applications usage of an Azure OpenAI model exceeds the token quota limits, then the service will respond with a Rate Limit Error (Error code 429).
When this error is encountered, there are a couple options available for handling it:
- Wait a minute - With the tokens quota limit being a rate limits of the maximum number of tokens allowed per minute, the application will be able to send more prompts to the model again after the quota resets each minute.
- Request a quota increase - It may be possible to get Microsoft to increase the token quota to a higher limit, but it's not guaranteed to be approved. This request can be made at https://aka.ms/oai/quotaincrease
Tips to Minimize Token Rate Limit Errors
Here are a few tips that can help to minimize an applications token rate limit errors:
- Retry Logic - Implement retry logic in the application so it will retry the call to the Azure OpenAI model, rather than throwing an exception the first time. This is generally best practices when consuming external APIs from applications so they can gracefully handle any unexpected exceptions.
- Scale Workload Gradually - Avoid increasing the workload of the application too quickly. By gradually increasing the scale of the workload.
- Asynchronous Load Patterns - While there are time sensitive operations that will require a response immediately, there are also operations that are able to be run more asynchronously. Background processes or other similar operations could be build in a way to perform a combination of rate limiting the applications own usage of the model, or even delaying calls until periods of the day where the application is under less load.
- Set
max_tokens- Setting a lowermax_tokenswhen calling the service when a short response is expected will limit the maximum number of tokens allowed for the generated answer. - Set
best_of- Setting a lowerbest_ofwhen calling the service enables the application to control the number of candidate completions generated and how many to return from the service.
Exceeding Token Limit for System message
When configuring a System message to guide the generated responses, there is a limit on how long the System message can be. The token limit for the System message is 400 tokens.
If the System message provided is more than 400 tokens, the rest of the tokens beyond the first 400 will be ignored.